
Accelerating Code Completion with Fireworks Fast LLM Inference
By Fireworks.ai|10/11/2023
At Fireworks.ai, we provide the world's fastest LLM inference platform which enables developers to run, fine-tune, deploy, and share large language models (LLMs). The Fireworks GenAI Platform delivers significantly lower costs than comparable providers. Our inference platform is used by companies and developers to solve real-world problems with high-performing and optimized LLMs.
To access the models for free today, you can sign up for an API key at fireworks.ai_.
In this post, we highlight a recent release by Sourcegraph that demonstrates the use of our inference platform to power fast and high-quality code completion, which is essential to build production-grade AI-powered coding assistants. We specifically highlight the recent integration of our blazing-fast LLM inference to the popular AI-powered coding assistant, Cody.
Fireworks.ai 🤝 Sourcegraph
Modern developers seek tools that provide intelligent, quick code suggestions to enhance productivity and mitigate the time spent on repetitive coding tasks. This has led to the high use of popular AI-powered code-generating tools like Copilot and Cody. As AI-powered assistants like Cody are widely adopted, there is also a high demand for inference speed and output quality which is where the Fireworks fast LLM inference platform shines.
Sourcegraph's Cody now utilizes the StarCoder model running on Fireworks for the majority of its completion in the community edition. This has notably improved code autocomplete, elevating the Completion Acceptance Rate (CAR) from 15% to 30%. Cody's E2E multi-line latency reduces from 3.4s to 2.4s, and single-line latencies reduce from 2.0s to 1.1s. Overall, Fireworks accelerated the backend latency by more than 2x. These leaps in performance — enhanced speed and efficiency, significantly improve user experience and productivity.
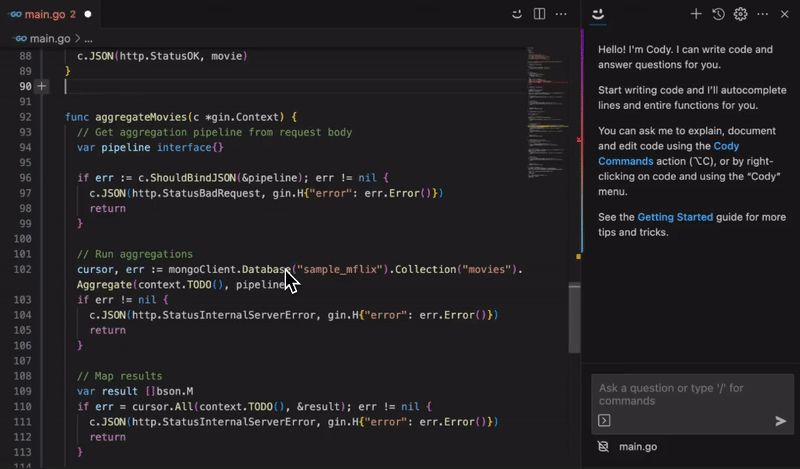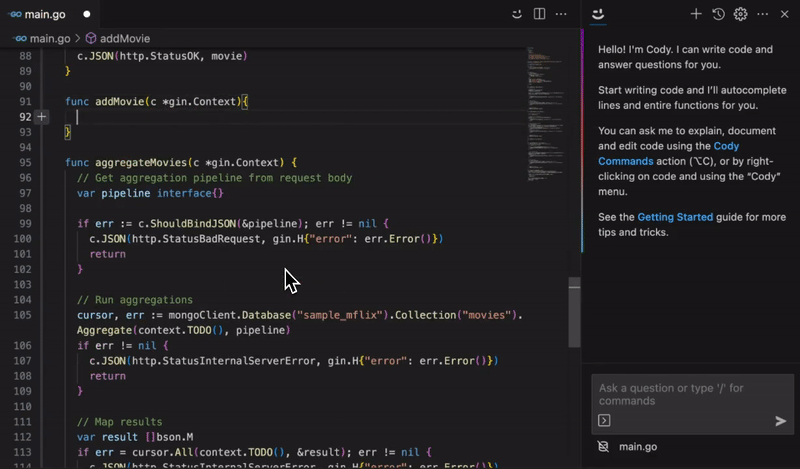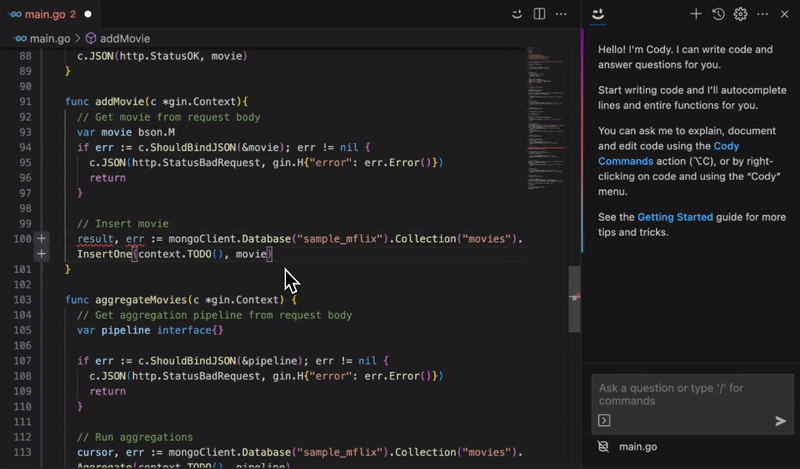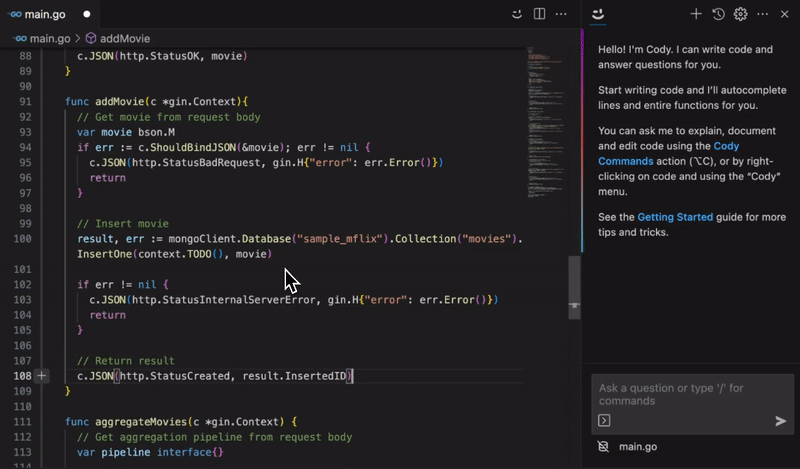
Efficient Code Completion
The Fireworks platform provides state-of-the-art machine performance for latency-optimized and throughput-optimized settings and cost reduction (up to 20–120x lower) for affordable serving.
The efficiency and affordability of custom LLMs are key to enabling production-grade code completion applications. We enable this through our highly optimized inference service and key deep system optimization and model-system co-optimization techniques, including multi/group query attention (MQA), PyTorch runtime optimization, and infrastructure optimizations.
Below we provide some benchmarking results after running a StarCoder model with a setup that includes different batch sizes, 8 GPUs (A100), 2K prompt length, and a generation length of 50 tokens. Our service latency is consistently better by 3.5x or more across batch sizes as compared to vLLM. This is deployed in our multi-tenant cluster and we have even more performance optimized setup driving overall 7x lower latency. Overall, the Fireworks inference platform offers latencies that are significantly lower than comparable open-source offerings.

Try Out Code Infilling Now!
Interested in code generation and infilling? Fireworks simplifies the process with our fast and optimized models. Our API lets you easily generate missing code blocks, enhancing features like type inferencing or docstring generation, without the hassle of having to set everything up from scratch yourself.
Explore the details in our previous post: Simplifying Code Infilling with Code Llama and Fireworks AI
Wrapping up
Sourcegraph's integration with Fireworks.ai underscores the potential of combining fast inference with open-source LLMs in the realm of high-quality code generation and completion. Cody, which is also open-source, demonstrates that models hosted through our optimized inference service can significantly enhance performance and user experience.
Developers can now experience reduced latency and improved code completion quality, ensuring a smoother and more productive coding experience with AI coding assistants.
Sign up for an API key to start using our collection of models for code completion and other use cases like summarization and conversational agents. The Fireworks Developer tier is free to use to get you going easily.