
Multi-Query Attention is All You Need
By Fireworks.ai, James K Reed, Dmytro Dzhulgakov, Dmytro Ivchenko, Lin Qiao|7/12/2023
This post explores how a nascent modeling technique called Multi-Query Attention (MQA) significantly improves machine performance and efficiency for language inference tasks such as summarization, question answering, and retrieval-augmented generation. By using MQA-based efficiency techniques, users can get 11x better throughput and 30% lower latency on inference. Models that use Multi-Query Attention include LLaMA-v2 and Falcon. Further, we explore a technique for executing MQA in a distributed fashion to further improve latency. Finally, we show how the Fireworks Gen AI Platform allows you to tune LLMs to solve your business tasks and efficiently serve these models using the described techniques.
Note that literature released after this blog post refers to Multi-Query Attention with multiple KV heads as “Group-Query Attention”.
Efficient LLM Inference
Large Language Models (LLMs) based on the Transformer architecture have emerged as an effective technique for language tasks, including summarization, question answering (Q&A), and retrieval-augmented generation. However, using these models comes at a very high computational cost, and their execution is primarily done via compute accelerators like NVIDIA GPUs.
Input and outputs to LLMs are represented as sequences of tokens (e.g. words). Training or fine-tuning LLMs that can handle long sequences (i.e. that have a long context window) is an actively evolving field. Most OSS LLM base models are pre-trained with a 2K context window. In more and more use cases like document summarization or context-based question answering, the sequence length processed by the LLM can grow quite large–into thousands to tens of thousands of tokens. In the future, we believe long sequence lengths will be the new norm for most LLM use cases. But long sequences also have significant efficiency implications for the cost of inference.
System performance for inference can be improved without changing the model through several techniques, including:
- Saving computed state between iterations of the inference process (KV-caching)
- Batching multiple sequences together during inference to reuse computational resources (batching) and, as an extension, continuously batching concurrent requests (e.g. Yu et al.)
- Memory allocation strategies to reduce memory fragmentation and maximize batch size. (e.g. VLLM)
However, the most effective way to improve inference performance is to co-design the model architecture and the system architecture. In this article, we highlight one such joint technique, Multi-Query Attention (MQA), which dramatically reduces both memory space and memory bandwidth needed for inference computation. Space savings are proportional to the number of tokens, so it’s particularly beneficial for long sequences. Optimizing for MQA can lead to 11x better throughput and 30% lower latency in our benchmarks compared to the best openly available baselines without MQA.
Background - Multi-Head Attention
Much of LLMs' language expressivity comes from mixing context across sequences via the attention operation. Vaswani et al. propose Multi-Head Attention as the following mathematical operation:
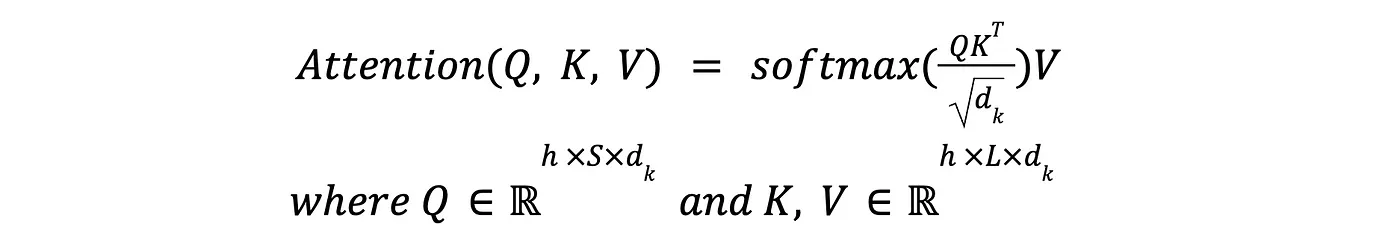
Multi-Head Attention Definition
Here h represents the number of “heads” in the operation, S and L represent input and output sequence lengths (respectively), and d_k represents the hidden dimensionality of the model architecture.
Equivalently in PyTorch code, we can write (with an extra batch dimension N):
Q = torch.randn(N, h, S, d_k)
K = torch.randn(N, h, L, d_k)
V = torch.randn(N, h, L, d_k)
# <...>
logits = torch.matmul(Q, K.transpose(2, 3)) # Output shape [N, h, S, L]
softmax_out = torch.softmax(logits / math.sqrt(d_k), dim=-1) # Output shape [N, h, S, L]
attn_out = torch.matmul(softmax_out, V) # Output shape [N, h, S, d\_k\]Note that we have two sequence lengths: one that applies to our Q value and one that applies to both K and V values. During inference, we typically use incremental generation, where we progressively feed values into the network a single token at a time (i.e. S = 1) and compute K and V across the tokens seen so far (i.e. L grows as generation proceeds). As a result, K and V grow progressively as the output sequence is generated, and a common optimization technique is to use a mutable KV-cache across iterations. The inner loop of multi-head attention then looks like this:
# Cached K and V values across iterations
K = torch.randn(N, h, ..., d_k)
V = torch.randn(N, h, ..., d_k)
# Single-step QKV values computed during sequence generation
Q_incr = torch.randn(N, h, 1, d_k)
K_incr = torch.randn(N, h, 1, d_k)
V_incr = torch.randn(N, h, 1, d_k)
# <...>
# Update KV-cache
K = torch.cat([K, K_incr], dim=-2)
V = torch.cat([V, V_incr], dim=-2)
# Compute attention (L is sequence length so far)
logits = torch.matmul(Q_incr, K.transpose(2, 3)) # Output shape [N, h, 1, L]
softmax_out = torch.softmax(logits / math.sqrt(d_k), dim=-1) # Output shape [N, h, 1, L]
attn_out = torch.matmul(softmax_out, V) # Output shape [N, h, 1, d_k]Multi-Query Attention
Shazeer (2019) proposed a refinement to the Multi-Head Attention (MHA) algorithm called Multi-Query Attention (MQA), which improves machine efficiency of attention while incurring minimal accuracy degradation. The idea is simple: remove (or otherwise greatly reduce) the heads dimension h from the K and V values. Intuitively, we can say that in multi-head attention, the entire attention computation is replicated h times, whereas in multi-query attention, each “head” of the query value Q has the same K and V transformation applied to it. The incremental generation case looks like this:
# Cached K and V values across iterations
K = torch.randn(N, ..., d_k)
V = torch.randn(N, ..., d_k)
# Single-step QKV values computed during sequence generation
Q_incr = torch.randn(N, h, 1, d_k)
K_incr = torch.randn(N, 1, d_k)
V_incr = torch.randn(N, 1, d_k)
# <...>
# Update KV-cache
K = torch.cat([K, K_incr], dim=-2)
V = torch.cat([V, V_incr], dim=-2)
# Compute attention (L is sequence length so far)
# NB: K is broadcasted (repeated) out across Q's \`h\` dimension!
logits = torch.matmul(Q_incr, K.transpose(2, 3)) # Output shape [N, h, 1, L\]
softmax_out = torch.softmax(logits / math.sqrt(d_k), dim=-1) # Output shape [N, h, 1, L]
# NB: V is broadcasted (repeated) out across softmax_out's `h` dimension!
attn_out = torch.matmul(softmax_out, V) # Output shape [N, h, 1, d_k]
Multi-Query Attention
Note that the amount of computation performed by incremental MQA is similar to that of incremental MHA. The key difference is in the reduced amount of data read/written from memory with MQA. This has implications for both performance (via arithmetic intensity increase) and space (via a decrease in the amount of KV-cache data stored in memory). In the next section, we will go into more detail about these effects.
Hardware Efficiency of MQA
Modern computer architectures have unbalanced computational and memory speeds. Arithmetic computation is much faster than memory access, and as processor generations advance, this gap becomes even wider. We can quantify this gap by comparing arithmetic throughput (measured in FLOPS) and memory bandwidth (measured in bytes per second).
We can consult the chip's datasheet for a given processor to find these numbers, for example, for the NVIDIA A100. We see that this chip can sustain 19.5 TeraFLOPS computation (using fp32 computation) and approximately 2 terabytes/second memory bandwidth (note we do not compare Tensor Core performance due to non-trivial data access pattern, but the same argument applies when using TensorCores). To sustain the 19.5 TFLOPs computation, we would need to ingest at least 156 TB/s of data from memory (assuming 4 bytes input + 4 bytes output per FLOPS). This is significantly higher than what the device’s memory bandwidth can sustain, so we become memory-bandwidth bound, i.e. memory is the main limiting factor in performance.
To use the device's arithmetic resources to their full potential, we must re-use data values across multiple arithmetic operations. The degree to which data values are re-used for a given computation is called arithmetic intensity, which is the ratio between the number of compute operations and the size of data read/written to memory (an analogue to the flop/byte ratio we computed above but for a computation rather than for hardware). A clean intuitive model to describe the effect of arithmetic intensity on modern processors is the roofline model.

Roofline Model (https://en.wikipedia.org/wiki/Roofline_model)
Computations are memory-bandwidth bound until they reach a high enough arithmetic intensity (determined by the processor's ratio of compute to memory capability). Beyond this point, they become compute-bound, and the full arithmetic performance of the processor is achieved.
The effect of multi-query attention on arithmetic intensity is two-fold:
- MQA reduces the number of bytes read from memory per arithmetic operation in the attention computation, thus increasing arithmetic intensity. This leads to a faster and more efficient attention computation.
- MQA also reduces the number of bytes that must be stored in memory for KV-cache values. This extra space allows us to increase the batch size (N in the above pseudocode), which has a similar effect of increasing arithmetic intensity for the program.
Models with MQA
Since MQA changes the semantics of attention, models generally must be trained with MQA support from the beginning. Recent results in Ainslie et al. (2023) show that MQA can be added later by fine-tuning a trained model with the MQA modification. However, this technique still requires about 5% of the original training volume, which is orders of magnitude higher than regular fine-tuning datasets.
Despite MQA being around since 2019, it has only recently been incorporated into publicly-released open-source models, spurred on by increasing emphasis on efficient production deployment of LLMs.
At the time of writing, there's only a handful of open source models that incorporate MQA:
- LLaMA-v2 from Meta AI.
- Falcon, developed by Technology Innovation Institute and released in April 2023
- SantaCoder (December 2022) and its bigger cousin StarCoder (April 2022), developed by the BigCode Project.
In this post, we will primarily focus on evaluating Falcon as it's a general foundation model with strong accuracy on standardized benchmarks. Currently, both Falcon 7B and 40B are among the leaders in the open-source LLM leaderboard in their size category (even with the recent corrections). Falcon models come with a permissive Apache 2.0 license that allows for commercial use.
MQA Implementation
Although MQA is fairly straightforward on a conceptual level (involving repeating, or “broadcasting”, K and V values within the attention computation), efficient implementations of it are hard to find in publicly available engines. The full attention computation (including the outer product, softmax, and value mixing) is usually implemented as a single CUDA kernel in packages like FlashAttention or VLLM's PagedAttention. These kernels expect the KV-cache values to be fully broadcasted beforehand to the correct number of heads to match the Q value.
To optimize for MQA specifically, we extend the custom attention kernel to handle broadcasting inline. Depending on the number of heads and GPU architecture, further optimizations are possible to more efficiently use GPU cache as the same head value in KV-cache interacts with many heads in Q.
The change to KV-cache allocation is simple. Instead of allocating a [num_layers, num_tokens, num_heads, head_dim] tensor we allocate [num_layers, num_tokens, num_heads_kv, head_dim]. Note that for larger models, num_head_kv is larger than 1, while still significantly lower than original num_heads (grouped MQA mentioned above). E.g. for Falcon-40B, num_heads=128, num_heads_kv=8.
Estimating the impact of MQA on maximum batch size is thus easy. The number of tokens that can fit in the KV-cache is determined by

And concurrent batch size is thus

For example, after loading a 40B model quantized in int8 on A100 80GB GPU, the remaining ~40GB are enough to fit ~13k tokens in the cache. With a moderate sequence length of 2000 it can process fit 6 requests in a batch. For more easily available GPUs like A6000/A40 with 48GB of RAM, less than 8GB are available for the cache, so only 1-2 sequences can fit. MQA allows for an increase in the maximum batch size by the ratio of the number of heads and KV heads. For Falcon 7B this factor is 71x and for Falcon 40B it is 16x.
MQA removes memory pressure and fragmentation as a consideration for most practical batch sizes. Thanks to MQA, it's less important to optimize for compact KV-cache allocation for new sequences-there's enough memory to accommodate some fragmentation. In our implementation, we still pre-allocate the KV-cache to guarantee predictable memory behavior.
Performance Results
We evaluate performance in terms of both latency and throughput.
We consider cost-effective latency-bounded serving. We issue a constant stream of input requests coming from several clients. Each client sends the requests continuously with a small random pause in between. This setup is representative of latency-sensitive use cases (e.g. chat) running under load as the service-level load balancing and auto-scaling make an individual server's request stream approximately uniform.
For each request, a prompt sequence is sampled in the range of [1000, 1500] tokens, and the number of tokens to be generated is sampled in a range of [100, 200] tokens. These are typical settings, as the base Falcon models have a context window limit of 2048.
We evaluate several hardware+model setups:
- Falcon-7B model in the original 16-bit precision on an inference-centric A10g 24GB GPU (g5 instances on AWS), with 16 concurrent requests
- Falcon-40B model weight-quantized to 8 bits on a more affordable A6000 48GB (available on CoreWeave) with 4 concurrent requests
- Falcon-40B model with longer sequence length. This uses a fine-tuned model for sequence lengths up to 8k using the approach from Chen at al (2023). We sample prompts in the range [6000, 6500]. The model is similarly weight-quantized to 8 bits on high-end A100 80GB (p4de instances on AWS) with 16 concurrent requests
The number of concurrent requests for each configuration was chosen to have latency in the human-acceptable range of completing the generation in 10-20 seconds while maximizing throughput on a single GPU (to improve cost-to-serve). For ease of comparison, we're considering single GPU setups. If optimizing for lower latency, a multi-GPU setup (covered below) would be beneficial.
We apply weight-only quantization to 8 bits, with computation happening in 16 bits. This approach doesn't require finetuning the model and doesn't cause any measurable accuracy change on standard benchmarks.
We benchmark the Fireworks runtime with and without MQA for comparison. All configurations use continuous batching, a variant of VLLM's PagedAttention, and efficient model implementation with custom kernels and CUDA graphs. Thus the baseline is strongly competitive.
It's worth noting that the original Falcon implementation on HuggingFace has an interface bug that breaks KV-cache behavior and makes generation prohibitively slow. See the Appendix below for more details. Our model implementation doesn't have this issue.

Latency Performance Results
We see that MQA improves latency under load in all three configurations by 30-40%. The improvement comes from the higher effective batch size inside the model enabled by a larger KV-cache capacity.
Second, we consider a purely throughput-oriented setup: we issue all requests to the server simultaneously and measure time to completion. This is representative of batch processing cases like offline document generation, editing, translation or summarization. Thus we set prompt and generation lengths to be the same.

Throughput Performance Results
We see that with Falcon-40B, 4k total tokens, and an A100 GPU (with 40GiB free memory), using MQA allows us to increase throughput by almost 3x thanks to the larger batch size. The effect is more pronounced on an A6000 GPU with 48Gb of RAM. Without MQA, the KV-cache capacity is very limited, and the GPU can't even fit a single long sequence. MQA makes A6000 usage practical, enabling long sequence processing and 10x+ higher throughput on shorter sequences.
Scaling: MQA + Model Parallel
Besides using MQA, quantization, and PagedAttention to optimize single-GPU performance for LLM inference, we can also scale attention across multiple GPUs. Shoeybi et al. propose Megatron-LM, which provides a method for efficiently dividing Transformer computation by splitting linear projections and intermediate element-wise computations across devices.

Sharded Attention (Shoeybi, et al.)

Sharded MLP (Shoeybi, et al.)
Under the Megatron-LM scheme, during inference, the initial projections out to Q, K, and V values are divided column-wise, i.e. each rank (GPU) produces only a subset of the heads for each of Q, K, and V. Each of the following operations until the final down-projection is algorithmically parallel across heads, so they can be carried out in parallel by multiple GPUs without interaction. The final down-projection then must sum up partial results from each rank, which is implemented with an AllReduce operation on the output value.
Sharding MQA is not as trivial as the head dimension is irregular between Q and K/V. This can be seen in the diagram below comparing the data layouts of a typical fused MHA QKV projection and the MQA QKV projection used in Falcon.

Sharded MHA/MQA Projection Matrix
In MHA, each of the Q, K, and V subsets of the matrix can be divided along the output dimension, and a final sharded matrix constructed by concatenating those pieces. In MQA, the number of heads that K and V have is less than that of Q. As such, many Q heads are grouped in with each pair of K and V heads. We cannot trivially split this matrix in the same way as we can split the MHA matrix. Instead, we use the following policy:
- Each group of Q heads is divided across ranks.
- Each group of K and V ranks is replicated, i.e. each rank holds all data for K and V.
This formulation is mathematically equivalent to single-rank MQA, but divides computation by splitting up the Q heads. The replication of K and V can be thought of as an offline “partial broadcast” of these values, and at runtime K and V are further broadcast over the Q heads that each rank holds. Partial results are combined with AllReduce in the final down-projection, as in MHA.
If the number of K and V heads is higher than 1 (but still smaller than Q), we apply a two-level sharding scheme. The first level of sharding is done to K and V heads (and corresponding groups of Q heads). The second level applies to each individual group of Q heads as described above. Pope et al (2022) propose sharding attention computations after the QKV projection by the batch dimension (i.e. data-parallel) to avoid replication of K and V across GPUs. We find that this approach is needed only if there's a single K and V head. Larger recent models tend to have several heads, e.g. Falcon 40B has 8.
Try Out Models with MQA on the Fireworks Gen AI Platform
Fireworks aims to accelerate new product innovation based on Gen AI. We offer a Gen AI experiment and production platform with top Gen AI OSS models. Our platform delivers rapid experimentation, minimized cost-to-serve in production, and data privacy. The platform emphasizes support for open models, which can be fine-tuned on your own data in your own infrastructure (cloud or on-prem). The fine-tuned model can then be uploaded to our inference service to serve your product requests with minimal costs to serve.
Our inference service is highly-optimized. We deliver the lowest latency and cost for the top open-source models, including Falcon and LLaMA family models mentioned in this article. More broadly, we foresee a continuing trend of such co-design, where models are designed with inference efficiency in mind. We apply deep system optimization and model-system co-optimization techniques, including MQA, PyTorch runtime optimization, and infrastructure optimizations for your customized models. Beside serving open-source models directly, we provide business recipes for fine-tuning models on customers' data and cost-efficient serving of the resulting customized models.
Reach out to us for our platform's closed beta to bring the power of Generative AI to your business. Stay tuned for product announcements, and follow us on Twitter or Threads for more technical deep dives.
Appendix: Performance Bug in Original Falcon Implementation
We noticed that the original implementation of Falcon models available on HuggingFace has an unfortunate bug in the model interface. The parameter representing the KV-cache is named inconsistently, and using Python's kwargs masks the issue.

Original Falcon Implementation
This bug effectively disables the KV-cache and makes the model process the entire cumulative sequence for every generated token (equivalent to model.generate(…, use_cache=False)). It leads to a significant slowdown even for single-batch generation on a small sequence length. Worse, because the lack of KV-caching increases computation quadratically, the generation of larger batch sizes or longer sequences becomes prohibitively slow. We saw a 5x+ slow down for batch size 16 and sequences of 128, while sequences longer than 1000 just time out. This behavior has been reported in some Twitter threads and the model repo discussions.
This issue is a good illustration of the importance of KV-cache for efficient LLM inference.